Behind the scenes at Monte Carlo simulations
Suppose your life cycle assessment shows that product A is better than B. Will this conclusion still hold if you take into account that most data is likely to fall in a range of possible values? That is, if you take into account the uncertainty in the inventory data?
Data Uncertainty Throughout Your LCA
All of your inventory data is uncertain to some extent. This data uncertainty can be described by a distribution that is characterized by a standard deviation or expressed in a range. It can be risky to do an LCA with uncertain data, especially if you’re going to use that LCA to compare the performance of two products. The uncertainties in the various data inputs all add up and can heavily influence your LCA results. If you happen to use sample values that are consistently on the low side of the various data ranges for product A’s LCA, and sample values that are consistently on the high side for product B’s LCA, you might think that product A performs better. Though, when you run these LCAs again with different data samples, you might get the opposite results, merely by chance.
To see the combined influence of all input uncertainties, people use a Monte Carlo analysis to calculate the uncertainty of the LCA results – how much of a range or spread there is in actual results, based on variable inputs. But what actually happens when you click ‘calculate’? It is not my intention to give you detailed instructions – for that, I refer to the SimaPro manual. Instead, I want to give you a chance to look behind the scenes in a Monte Carlo analysis.
Take The Gambling Approach
The Monte Carlo simulation method is named after the Monte Carlo casino in Monaco since it has an element of gambling in it. The moment you click ‘calculate’ in SimaPro’s uncertainty menu, a simulation starts. It takes a random value from the uncertainty distribution for each uncertain data input and calculates and stores the LCA results for this set of sampled values. The procedure is repeated an enormous number of times. Every time, SimaPro selects random values from the uncertainty distribution per data input, calculates the LCA results, and stores them. The stored LCA results of, for instance, 10000 iterations form an uncertainty distribution for the final outcome.
Laundry: A Mundane Example
Imagine you are modeling the environmental impacts for one kilogram of laundry to be washed in a washing machine. You start by considering how a washing machine is likely to be used, summarised in Figure 1. The amount of laundry that is put into the machine is probably not exactly the same for each washing cycle. Let’s assume that the amount of laundry per cycle is described by a normal distribution around an average of seven kilograms. How much detergent you use depends on your judgment of how much laundry you have and how dirty it is. You probably want to use as little as possible, but you’ll occasionally use a high dose. Let’s consider this a log-normal distribution. There are plenty more variables that are uncertain to some extent (e.g. the use of water, electricity, or fabric softener), and you can assign a distribution for each of them. If you run a Monte Carlo simulation on this model, SimaPro selects a random value from each assigned uncertainty distribution for each iteration. The calculated environmental impacts per kg of laundry will vary between iterations and together form an uncertainty distribution (see Figure 1, bottom right).

Figure 1. The uncertainty distributions of the inventory data determine the uncertainty distribution of the LCA results. An example of laundry. Picture of washing machine adapted from wikiHow under creative commons.
Uncertainty in industrial processes can generally be described by a log-normal distribution. This implies that values from the far right hand of the distribution will also be sampled. Using the mean to represent the most typical value or ‘best guess’ value, as we do with normal distributions, would misrepresent reality. For log-normal distributions, the ‘best guess’ is better represented by the median.
Comparing Washing Machines
Now, suppose that you want to compare the environmental impacts of washing machines A and B on freshwater eutrophication. To do so, you’re going to compare the uncertainty distributions for that environmental indicator – derived from a Monte Carlo simulation – for both washing machines. There is a reasonable chance that the uncertainty distributions of the LCA results overlap, as illustrated by the pink area in Figure 2.
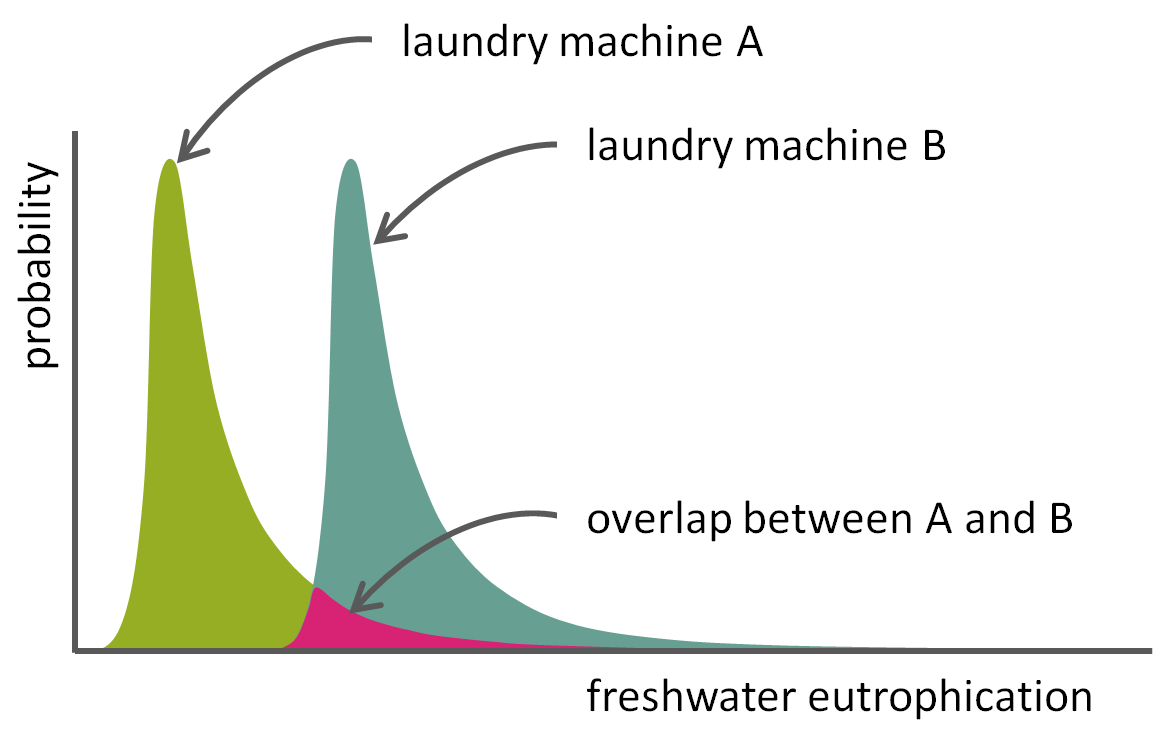
In SimaPro, you can specify that you want to do a Monte Carlo analysis to compare two products. The LCAs for the two products will run side by side, and for each iteration, SimaPro will calculate the value of ‘the impact of washing machine A minus the impact of washing machine B’. Together, these values form another probability distribution, which can then be used to decide which product is better, and how sure you are of that. Let’s say that in the example of Figure 2, washing machine B has a higher impact on freshwater eutrophication than washing machine A in 70% of runs – that means you have 70% certainty that A actually outperforms B on this indicator. Do you think this is sufficient evidence? Personally, I prefer 90% certainty as a minimum to consider the difference significant. Moreover, you are probably not just interested in freshwater eutrophication but in other impact categories as well. It may very well be that for those categories, washing machine A has a higher impact than washing machine B. Before you decide which product is better, therefore, you need to determine the certainty in all impact categories that are relevant for your LCA.
More Reasons Why You Want to Use Monte Carlo
As outlined above, if you are comparing the impacts of two washing machines, a Monte Carlo analysis can help you to determine whether the differences between them are significant or not, given the uncertainties in e.g. the amount of laundry per cycle, the use of detergent, water, electricity, or fabric softener.
But if the differences aren’t significant, is that because the products perform roughly the same or because there is too much uncertainty in the data? That brings up another great reason to use Monte Carlo analysis: it allows you to quantify the influence of the uncertainty in different data inputs on your LCA results, showing whether the data you collected is of sufficient quality and whether the uncertainty in your LCA results is acceptable. If the differences you found are significant, there is no need to collect data of higher quality, which means you save time. If the differences are not significant and the uncertainty is high, you can look for ways to reduce the overall uncertainty in your LCA results – for instance, by using product-specific data rather than average data.
Whatever your situation, the results from a Monte Carlo simulation can be a great aid in interpreting your results and the stability of your conclusions.
Laura Golsteijn
Senior Consultant
I am eager to increase the environmental awareness of our society, and I believe that everyone can contribute to a more sustainable world, every day. At PRé we provide companies with both the knowledge and the tools to improve their products and services. I am excited to work for an organisation that is involved in developing sustainable initiatives.